
ES中的Scirpt Score查询
Scirpt Score查询
ES提供的Script Score查询可以以编写脚本的方式对文档进行灵活打分,以实现自定义干预结果排名的目的。Script Score默认的脚本语言为Painless,在Painless中可以访问文档字段,也可以使用ES内置的函数,甚至可以通过给脚本传递参数这种方式联通内部和外部数据。
1.1 Painless简介
Painless语言是一种专门用于ES中的脚本语言,它使用了类似于Groovy的语法。ES使用了沙箱技术运行Painless,且在Painless中没有任何网络连接的功能,因此它在安全性方面是有保障的。Painless是被编译成JVM字节码后运行的,从语法上看是Java的子集。
1.变量
变量在使用之前必须先进性声明,其声明方式和Java保持一致。如果变量在声明时没有指定值,则使用变量类型对应的默认值。
2.数据类型
Painless支持的原始类型有byte、short、char、int、long、float、double和boolean。可以按照Java的方式声明它们:
int i=0;
boolean t=true;
double s;
在Painless中也可以使用引用类型,可以使用new关键字对引用类型进行初始化:
List l=new ArrayList();
字符串类型可以直接使用:
String a="abcde";
像引用类型一样,数组是使用new关键字分配的:
int[] a=new int[3];
a[0]=1;
a[1]=2;
a[2]=3;
数组的大小也可以是隐式的:
int[] x=new int[]{1,2,3};
Painless还支持使用def对动态类型的变量进行声明,它的作用是在声明时不指定类型而是在运行时判断数据类型,例如:
def x=5;
def y="abc"
3.条件和循环(不支持else if或者switch)
def a=10;
if(a>8){//条件判断
...
}
Painless支持for循环、while循环和do...while循环。
def result=0;
for(dedf a=0;a<10;a++){ //for循环
result=a+1;
}
1.2 在Script Score中使用Painless
在Script Score查询中可以使用Painless脚本进行打分脚本的开发,脚本你代码主体放在参数source的值中,注意,Script Score查询中的脚本代码必须有返回值并且类型为数值类型,如果没有返回值,则Script Score查询默认返回0。
这里定义酒店索引的结构如下:
PUT /hotel_painless
{
"mappings": {
"properties": {
"title":{
"type": "text"
},
"price":{
"type": "double"
},
"create_time":{
"type": "date"
},
"full_room":{
"type": "boolean"
},
"location":{
"type": "geo_point"
},
"doc_weight":{
"type": "integer"
},
"tags":{
"type": "keyword"
},
"comment_info":{ //定义comment_info字段类型为object
"properties": {
"favourable_comment":{ //定义favourable_comment字段类型为integer
"type":"integer"
},
"negative_comment":{
"type":"integer"
}
}
},
"hotel_vector":{ //定义hotel_vector字段类型为dense_vector
"type": "dense_vector",
"dims":5
}
}
}
}
如果运行报错,将注释代码删掉重新执行。
后边需要数据演示,向酒店索引中添加如下数据:
POST /_bulk
{"index":{"_index":"hotel_painless","_id":"001"}}
{"title":"文雅假日酒店","price":556.00,"create_time":"20200418120000","full_room":false,"location":{"lat":36.083078,"lon":120.37566},"doc_weight":30,"tags":["wifi","小型电影院"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0,3.2,5.8,1.2,0]}
{"index":{"_index":"hotel_painless","_id":"002"}}
{"title":"金都嘉怡假日酒店","price":337.00,"create_time":"20210315200000","full_room":false,"location":{"lat":39.915153,"lon":116.4030},"doc_weight":10,"tags":["wifi","免费早餐"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0.7,9.2,5.3,1.2,12.3]}
{"index":{"_index":"hotel_painless","_id":"003"}}
{"title":"金都欣欣酒店","price":200.00,"create_time":"20210509160000","full_room":true,"location":{"lat":39.186555,"lon":117.162007},"doc_weight":10,"tags":["会议厅","免费车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[6,3.2,0.4,9.3,0]}
{"index":{"_index":"hotel_painless","_id":"004"}}
{"title":"金都家至酒店","price":500.00,"create_time":"20210218080000","full_room":true,"location":{"lat":39.915343,"lon":116.422011},"doc_weight":50,"tags":["wifi","免费车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[0.7,3.2,5.1,2.9,0.1]}
{"index":{"_index":"hotel_painless","_id":"005"}}
{"title":"文雅精选酒店","price":800.00,"create_time":"20210101080000","full_room":true,"location":{"lat":39.918229,"lon":116.422011},"doc_weight":70,"tags":["wifi","充电车位"],"comment_info":{"favourable_comment":20,"negative_comment":10},"hotel_vector":[12.1,5.2,5.1,9.2,4.5]}
以下代码演示了使用脚本代码进行打分的基本方法:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {"title": "金都"}
},
"script":{
"source":"def a=1;def b=2;return a+b;"
}
}
}
}
也可以使用3个引号的形式将代码括起来;
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
def a=1;
def b=2;
return a+b;
"""
}
}
}
}
上面是带返回值的情况,下面的代码演示脚本代码不返回值的情况:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
def a=1;
def b=2;
"""
}
}
}
}
ES返回结果如下:
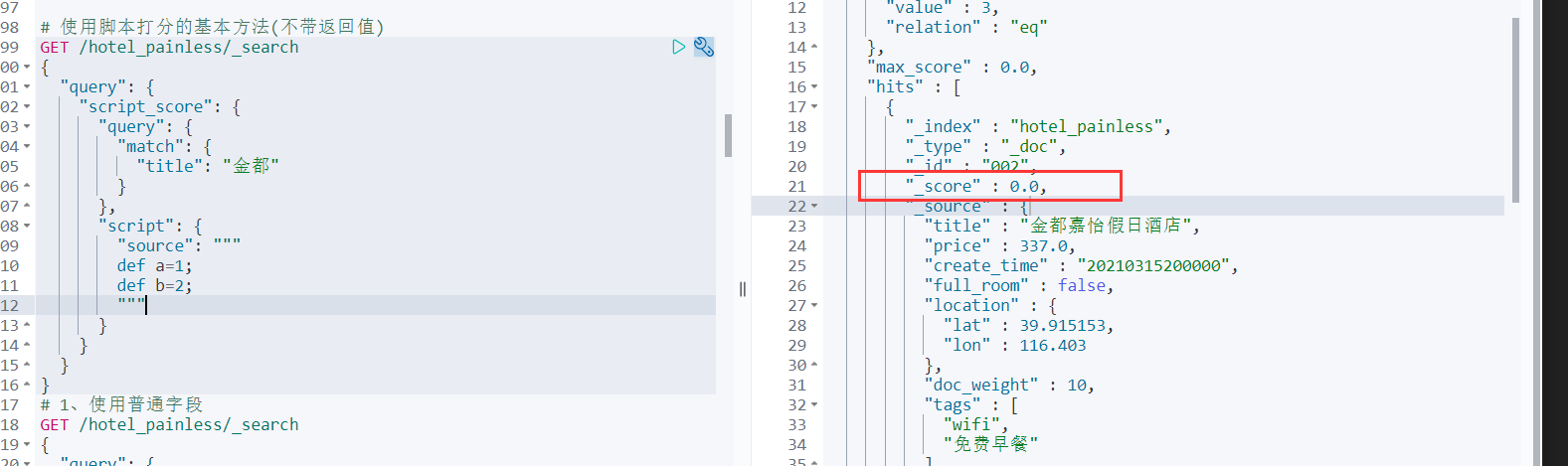
从上述结果可看出,由于Script Score的代码没有返回值,所以ES默认返回0,所有文档得分都为0。
1.3 使用文档数据
1.3.1 使用普通字段
如果字段属于基本数据类型,则可以通过params._source.$field.field_name获取字段的值。例如,在酒店索引中,price字段为double类型,doc_weight字段为integer类型。
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query":{
"match":{"title":"金都"}
},
"script":{
"source":"""
if(params._source.price>23){
return params._source.doc_weight;
}
return 0;
"""
}
}
}
}
如果想知道索引中的某些文档的某个字段是否为空,则可以通过null值进行判断:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query":{
"match":{"title":"金都"}
},
"script":{
"source":"""
if(params._source.price!=null){
return params._source.price;
}
return 0;
"""
}
}
}
}
也可以使用doc['$field']来引用字段,使用doc['$field'].value引用字段的值。下面DSL和上面的DSL效果是相同的。
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query":{
"match":{"title":"金都"}
},
"script":{
"source":"""
if(doc['price']!=null){
return doc['price'].value;
}
return 0;
"""
}
}
}
}

1.3.2 使用数组字段
当字段类型为数组时,可以直接使用for循环遍历数组中的元素,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query":{
"match":{"title":"金都"}
},
"script":{
"source":"""
for(def tag:params._source.tags){
if('wifi'==tag){
return 1;
}
}
return 0;
"""
}
}
}
}
如果需要判断数组长度,则可以使用length属性。
# 判断数组长度,使用length属性
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
if(params._source.tags.length>1){
return 1;
}
return 0;
"""
}
}
}
}
1.3.3 使用object类型的字段
在访问object类型字段中的值时,除了使用"."操作符引用该object类型的字段外,对其他字段的访问与访问索引的普通字段类似。例如,酒店评论中的好评数据,可以使用params._source.comment_info['favourable_comment']来引用,以下DSL将评论数作为酒店的分值返回。
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
def comment=0;
if(params._source.comment_info!=null){
if(params._source.comment_info.containsKey('favourable_comment')){
//引用对象类型字段中的数据
comment+=params._source.comment_info['favourable_comment'];
}
if(params._source.comment_info.containsKey('negative_comment')){
comment+=params._source.comment_info['negative_comment'];
}
}
return comment;
"""
}
}
}
}
1.3.4 使用文档评分
在使用match匹配搜索时,ES会对文档进行BM25算法打分,尽管BM25很好地完成了评分/相关性,但有时需要根据业务需求在原有评分的基础上对相关性进行干预。可有使用_score直接获取BM25算法的打分数值,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
return _score*params._source.doc_weight; //使用文档原始评分
"""
}
}
}
}
在上述DSL中,ES将文本匹配分乘以文档的权重作为文档的最终分数返回。
1.4 向脚本传参
Painless不提供任何网络访问的功能,假设有一部分打分相关参数存储在Redis中,应该如何传递数据?答案就是向Painless传参。假设我们已经通过Java客户端连接Redis获取到了某个特定搜索应该设定的权重值,那么在索引中搜索时,可以通过params关键字定义参数名称并设置其值,在代码中通过params['$para']这种形式进行引用,示例如下。
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
return params['query_weight']; //引用传递的参数值
""",
"params":{
"query_weight":10 //向脚本传参
}
}
}
}
}
在上面的代码中,首先将query_weight参数传递给打分脚本,然后再Painless代码中使用params['query_weight']进行参数的获取,此时就完成了参数的传递。
如果有多个参数,可以在params中进行定义,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
def a=1;
def b=2;
if(a+b>2){
return params['query_weight1'];
}
return params['query_weight2'];
""",
"params": {
"query_weight1": 10,
"query_weight2": 20
}
}
}
}
}
1.5 在Script Score中使用函数
在Function Score查询时,我们知道其中可以使用一些ES内置的预定义函数进行打分干预。同样,在Script Score中也可以使用这些函数。
1.5.1 saturation函数
saturation,它是计算饱和度的函数,其相当于计算占比,即:
示例为:
return saturation(params._source.comment_info.favourable_comment,params._source.comment_info.negative_comment);
以上代码中,文档的分值为酒店的好评率。
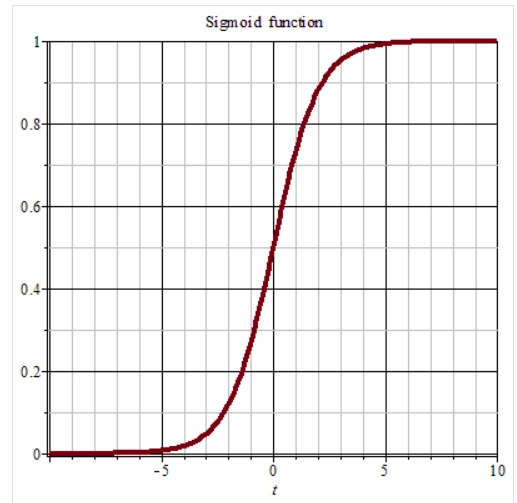
1.5.2 sigmoid函数
sigmoid函数在处理数值型数据时将其值的变换值映射到0~1,它的计算公式如下:
下图为sigmoid函数图像。
在使用Function Score时,sigmoid函数可以对某个字段的数据进行相应的处理,以下代码直接返回调用sigmoid函数处理doc_weight字段后的值:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
return sigmoid(params._source.doc_weight,2,1); //使用sigmod函数
"""
}
}
}
}
1.5.3 使用随机函数
在使用ES的搜索结果时,如果希望给不同用户推荐的商品排序是不同的,可以使用随机函数对上皮的打分进行控制。Script Score中的randomScore函数可以产生0\sim 1的小数(不包含边界值),其使用方式为randomScore(<seed>,<fieldName>),其中,seed为随机数种子,fieldName为非必传参数,为空时ES将使用Lucene文档的ID值作为该参数的值。
在一般情况下,seed参数是由外部传递进来的,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "金都"
}
},
"script": {
"source": """
return randomScore(params.uuidHash); //使用随机函数
""",
"params":{
"uuidHash":102322
}
}
}
}
}
在上面DSL中,每次搜索时都可以给脚本代码传递不同用户ID的哈希值,对应的参数名称为uuidHash,脚本代码会根据不同的uuidHash产生不同的随机值,因此每个用户的查询文档的排序值就不同。
1.5.4 使用向量计算函数
ES支持向量数据类型,一般情况下,索引中文档的向量是事先用模型计算完成的,如下图所示。

酒店的向量存储在ES中后,需要给定一个查询向量,对索引中的酒店文档向量按照向量相似度计算的算法进行查询。
cosineSimilarity函数可以计算给定查询向量和文档向量之间的余弦相似度,因为余弦值可能有负数,但是脚本返回值必须大于或等于0,所以一般对其进行加1处理,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "文雅"
}
},
"script": {
"source": """
//使用向量计算函数
return 1+cosineSimilarity(params.query_vec,'hotel_vector')
""",
"params":{
"query_vec":[12.1,5.2,5.1,9.2,4.5]
}
}
}
}
}
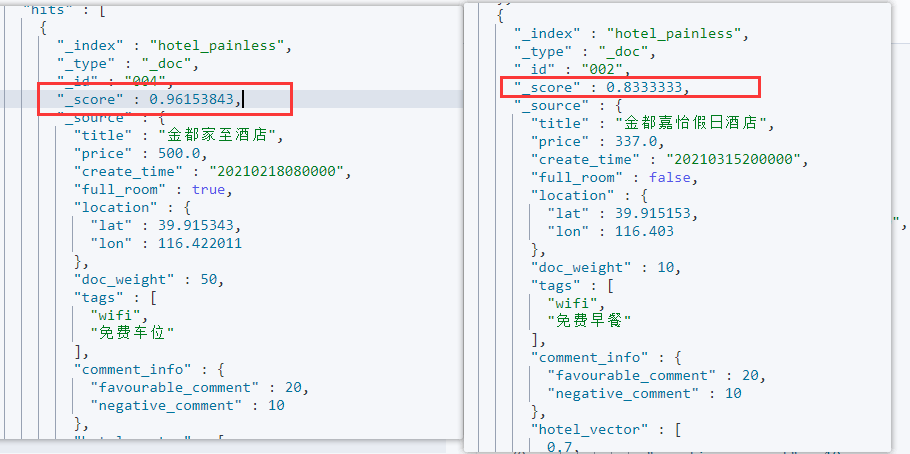
返回结果如下:
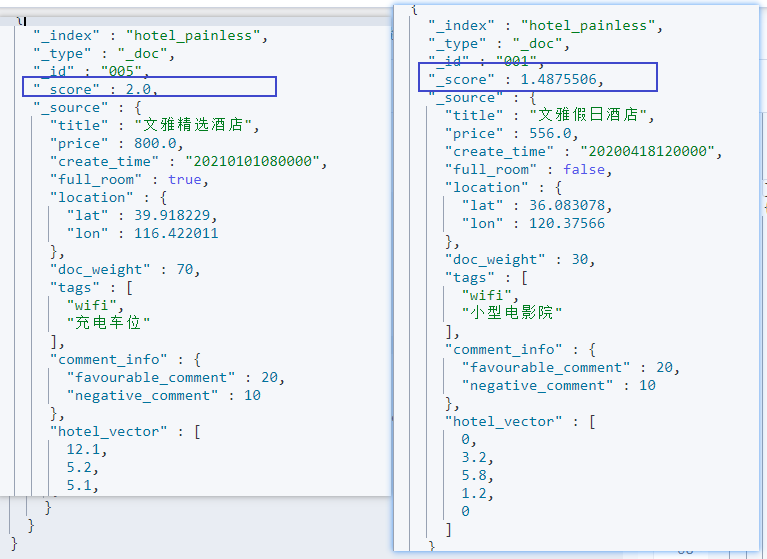
通过结果可以看到,酒店名称包含“文雅”的有文档005和文档001,查询的酒店向量和文档005的酒店向量是相同的,因此计算其consin值为1,再加上之前的1,文档005的分数为2。
文档001和查询向量的consin值为0.4875506,再加上之前的1,文档001的分数为1.4875506。也就是说,最终的文档排序是和向量相似度正相关的。
dotProduct函数可以计算给定查询向量和文档向量之间的点乘值,因为点乘值也可能是负数,所以在返回值时需要保证该值为正数或者0.可以使用sigmoid函数进行处理,DSL如下:
# dotProduct函数
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "文雅"
}
},
"script": {
"source": """
//使用向量计算函数
def dot=dotProduct(params.query_vec,'hotel_vector');
return sigmoid(1,Math.E,-dot);//使用sigmoid函数使返回值不是负数
""",
"params": {
"query_vec": [ //传递的向量参数
12.1,
5.2,
5.1,
9.2,
4.5
]
}
}
}
}
}
l1norm和l2norm函数可以计算给定查询向量和文档向量之间的距离,其中,l1norm用来计算向量之间的曼哈顿距离,l2norm用来计算向量之间的欧氏距离。与余弦相似度不同,距离越小代表向量越接近,因此返回值取其倒数即可。
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "文雅"
}
},
"script": {
"source": """
def norm = l1norm(params.query_vec,'hotel_vector');
return 1/(1+norm);
""",
"params": {
"query_vec": [
12.1,
5.2,
5.1,
9.2,
4.5
]
}
}
}
}
}
在上述实例中对分母进行了加1处理,是因为向量的距离可能为0,加1处理后能保障分母不为0.
1.5.5 使用衰减函数
在Script Score中使用衰减函数和在Function Score中是类似的,DSL如下:
GET /hotel_painless/_search
{
"query": {
"script_score": {
"query": {
"match": {
"title": "文雅"
}
},
"script": {
"source": """
//使用高斯衰减函数
double distanceGauss=decayGeoGauss(params.origin,params.scale,params.offset,params.decay,doc['location'].value);
return distanceGauss;
""",
"params": {
"origin":"39.915143,116.5049",
"offset":"1km",
"scale":"2km",
"decay":0.4
}
}
}
}
}

1.6 在Java客户端中使用Script Score
在Java客户端中,如果需要为searchSourceBuilder对象构建ScriptScoreQueryBuilder对象,可以先创建Script的实例,然后使用Script实例构建ScriptScoreQueryBuilder对象。Script的构造函数支持传递字符串形式的代码,另外,在Script的构造函数中还可以为脚本传递参数,可以创建一个Map对象对参数进行封装。示例代码如下:
@Test
public void getScriptScoreQuery(){
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "金都");
//编写脚本代码
String scoreScript = new StringBuffer()
.append("int weight=10;\n")
.append("def random=randomScore(params.uuidHash);\n")
.append(" return weight*random;").toString();
Map paraMap=new HashMap();
paraMap.put("uuidHash",234537);//设置传递到脚本的参数
//创建脚本对象
Script script = new Script(Script.DEFAULT_SCRIPT_TYPE, "painless", scoreScript, paraMap);
//创建ScriptScore查询builder
ScriptScoreQueryBuilder scriptScoreQueryBuilder = QueryBuilders.scriptScoreQuery(matchQueryBuilder, script);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(scriptScoreQueryBuilder);
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel_painless");
searchRequest.source(searchSourceBuilder);//设置查询请求
printResult(searchRequest);//打印搜索结果
}
//打印方法封装,方便查看结果
public void printResult(SearchRequest searchRequest) {
try {
//执行搜索
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取搜索结果集
SearchHits searchHits = searchResponse.getHits();
for (SearchHit searchHit : searchHits) {
String index=searchHit.getIndex(); //获取索引名称
String id=searchHit.getId(); //获取文档_id
float score = searchHit.getScore(); //获取得分
String source = searchHit.getSourceAsString();//获取文档内容
System.out.println("index="+index+",id="+id+",score="+score+",source="+source);
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}

- 0
- 0
-
分享