
ES聚合指标
聚合
当用户使用搜索引擎完成搜索后,在展示结果钟需要进行进一步的筛选,而筛选的维度需要根据当前的搜索结果进行汇总,这就用到了聚合技术。聚合的需求在很多应用程序钟都有所体现,例如在京东搜索“咸鸭蛋”,然后点击搜索界面钟的筛选按钮,在弹出的界面钟可以对当前的搜索结果进行进一步的过滤。例如,可以重价格区间、品牌、分类i、个数等维度分别进行筛选。

为方面介绍后续内容,这里定义酒店的索引如下:
PUT /hotel_poly
{
"settings": {
"number_of_shards": 1 //指定主分片个数为1
},
"mappings": {
"properties": {
"title":{
"type": "text"
},
"city":{
"type": "keyword"
},
"price":{
"type": "double"
},
"create_time":{
"type": "date"
},
"full_room":{
"type": "boolean"
},
"location":{
"type": "geo_point"
},
"tags":{
"type": "keyword"
},
"comment_info":{
"properties": {
"favourable_comment":{
"type":"integer"
},
"negative_comment":{
"type":"integer"
}
}
}
}
}
}
向索引中写入示例数据
POST /_bulk
{"index":{"_index":"hotel_poly","_id":"001"}}
{"title":"文雅假日酒店","city":"北京","price":556.00,"create_time":"20200418120000","full_room":true,"location":{"lat":39.938838,"lon":106.449112},"tags":["wifi","小型电影院"],"comment_info":{"favourable_comment":20,"negative_comment":10}}
{"index":{"_index":"hotel_poly","_id":"002"}}
{"title":"金都嘉怡假日酒店","city":"北京","create_time":"20210315200000","full_room":false,"location":{"lat":39.915153,"lon":116.4030},"tags":["wifi","免费早餐"],"comment_info":{"favourable_comment":20,"negative_comment":10}}
{"index":{"_index":"hotel_poly","_id":"003"}}
{"title":"金都假日酒店","city":"北京","price":200.00,"create_time":"20210509160000","full_room":true,"location":{"lat":40.002096,"lon":116.386673},"comment_info":{"favourable_comment":20,"negative_comment":10}}
{"index":{"_index":"hotel_poly","_id":"004"}}
{"title":"金都假日酒店","city":"天津","price":500.00,"create_time":"20210218080000","full_room":false,"location":{"lat":39.155004,"lon":117.203976},"tags":["wifi","免费车位"]}
{"index":{"_index":"hotel_poly","_id":"005"}}
{"title":"文雅精选酒店","city":"天津","price":800.00,"create_time":"20210101080000","full_room":true,"location":{"lat":39.178447,"lon":117.219999},"tags":["wifi","充电车位"],"comment_info":{"favourable_comment":20,"negative_comment":10}}
1.1 聚合指标
在进行聚合搜索时,聚合的指标业务需求不仅是文档数量。例如,在酒店搜索场景中,我们希望看到以当前位置为中心点,周边各个区域酒店的平均加个。
1.1.1 常见的聚合指标
在搜索聚合时,用户可能关注字段的相关统计信息,例如平均值、最大值、最小值及加和值。例如,用户在使用一个二手房交易搜索引擎进行搜索时,可能会关注当前城市各个区域的房产平均价格。用户在搜索酒店时,也可能会关注附近各个区域酒店的最低价格。
ES聚合请求的地址也是索引的搜索地址,可以使用aggs子句封装聚合请求。
当使用avg子句进行平均值的聚合时,可以在avg子句中指定聚合的字段。在默认情况下,查询将匹配所有文档,如果不需要返回匹配的文档信息,最好将返回的文档个数设置为0。这样既可以让结果看起来更整洁,又可以提高查询速度。
下面的DSL将查询所有酒店的平均价格并且不反悔匹配的文档信息。
GET /hotel_poly/_search
{
"size": 0,
"aggs": {
"my_agg": { //聚合名称
"avg": {
"field": "price" //计算文档的平均价格
}
}
}
}
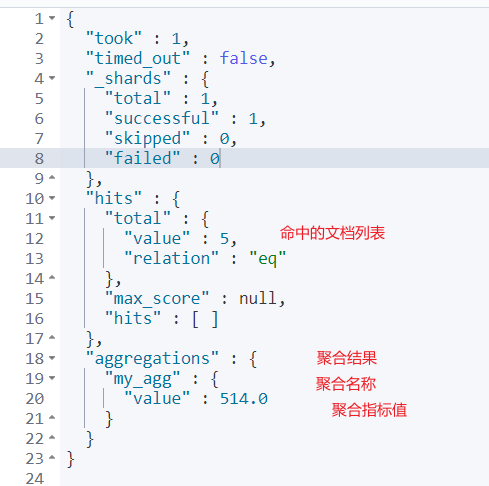
ES返回结果如下:
在上面的搜索结果中,索引的5个文档全部命中,由于DSL设置size为0,所以命中文档的信息没有显示。在搜索结果的aggregations子句中存储着聚合结果,其中my_agg是聚合的名称,其对应的value值就是具体聚合结果,即酒店的平均价格。
如果聚合的指标字段不是ES的基本类型,例如object类型,则可以使用点运算符进行引用。下面的DSL演示了该用法:
GET /hotel_poly/_search
{
"size": 0,
"aggs":{
"my_agg":{
"avg": {
"field": "comment_info.favourable_comment"
}
}
}
}

与平均值类似,最大值、最小值及加和值分别使用
max、min和sum子句进行聚合,不再赘述。
以下代码演示了在Java中使用聚合计算平均值的逻辑。
@Test
public void getAvgAggSearch() throws IOException {
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel_poly");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String aggName="my_agg"; //聚合的名称
//定义avg聚合,指定字段为price
AvgAggregationBuilder aggregationBuilder = AggregationBuilders.avg(aggName).field("price");
searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合
searchRequest.source(searchSourceBuilder); //设置查询请求
//执行查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Avg avg = aggregations.get(aggName); //获取avg聚合返回的对象
String key = avg.getName(); //获取聚合名称
double avgValue = avg.getValue();
System.out.println("key="+key+",aggValue="+avgValue);
}

为了避免多次请求,ES还提供了**stats聚合**。stats聚合可以将对应字段的最大值、最小值、平均值及加和值一起计算并返回计算结果。下面的DSL展示了stats的用法。
GET /hotel_poly/_search
{
"size": 0,
"aggs":{
"my_agg":{
"stats": {
"field": "price"
}
}
}
}

以下代码演示了在Java中使用stats聚合的逻辑。
@Test
public void getStatsAggSearch() throws IOException{
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel_poly");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String aggName="my_agg"; //聚合的名称
//定义avg聚合,指定字段为price
StatsAggregationBuilder aggregationBuilder = AggregationBuilders.stats(aggName).field("price");
searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合
searchRequest.source(searchSourceBuilder); //设置查询请求
//执行查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
Stats stats = aggregations.get(aggName); //获取stats聚合返回的对象
String key = stats.getName();
double sumValue=stats.getSum(); //获取聚合加和值
double avgVal=stats.getAvg(); //获取聚合平均值
double countVal=stats.getCount(); //获取聚合文档数量值
double maxVal=stats.getMax(); //获取聚合最大值
double minVal=stats.getMin(); //获取聚合最小值
log.info("key={}",key); //打印聚合名称
log.info("sumVal={},avgVal={},countVal={},maxVal={},minVal={}",sumValue,avgVal,countVal,maxVal,minVal);
}

1.1.2 空值处理
在索引中的一部分文档很可能其某些字段是缺失的,在介绍空值处理前,首先介绍ES聚合查询提供的value_count聚合,该聚合用于统计字段非空值的个数。
# value_count聚合统计price字段中非空值的个数
GET /hotel_poly/_search
{
"size": 0,
"aggs":{
"my_agg":{
"value_count": {
"field": "price"
}
}
}
}

通过上述结果可以看到,当前索引中price字段中的非空值有4个。
以下代码演示了在Java中使用value_count对price字段进行聚合的逻辑。
public void getValueCountAggSearch() throws IOException{
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel_poly");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String aggName="my_agg"; //聚合的名称
//定义avg聚合,指定字段为price
ValueCountAggregationBuilder aggregationBuilder = AggregationBuilders.count(aggName).field("price");
searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合
searchRequest.source(searchSourceBuilder); //设置查询请求
//执行查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
//获取value_count聚合返回的对象
ValueCount valueCount = aggregations.get(aggName);
String key = valueCount.getName();
long count = valueCount.getValue();
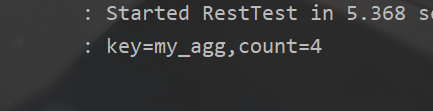
log.info("key={},count={}",key,count);
}
需要说明的是,如果判断的字段是数组类型,则value_count统计的是符合条件的所有文档中该字段数组中非空元素个数的总和,而不是数组的个数总和。
下面的DSL用于统计tags字段数组中非空元素个数的总和。
#统计tags字段数组钟非空元素个数的总和
GET /hotel_poly/_search
{
"size": 0,
"aggs":{
"my_agg":{
"value_count": {
"field": "tags"
}
}
}
}
在索引的5个文档中,除去文档003没有tags字段外,其他4个文档的tags字段数组中各有两个元素,因此聚合的值为2\times 4=8个,ES返回结果如下:

上面的结果中,aggregations.my_agg.value的值为8,这和前面计算的数值相等,验证了使用value_count对数组字段进行聚合时,ES返回的结果是所有数组元素的个数总和。
如果需要以空值字段的数据作为聚合指标对其进行聚合,可以在指标统计中通过missing参数指定填充值对空值进行填充。
以下示例演示了对price字段进行聚合,并设定了当字段值为空值时使用100进行替代的DSL。
# missing参数指定填充值对空值进行填充
GET /hotel_poly/_search
{
"size": 0,
"aggs": {
"my_agg": {
"sum":{
"field": "price",
"missing": 100 //计算加和值时将price字段中的空值用100代替
}
}
}
}
在索引中,文档002的price字段为空,因此被填充为100,文档001、003、004和005的price字段分别为556、200、500和800,因此符合聚合的值应该是556+100+200+500+800=2156。ES返回结果如下:

以下代码演示了在Java中当聚合指标为空值时指定填充之的逻辑。
@Test
public void getSumAggSearch() throws IOException{
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel_poly");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
String aggName="my_agg"; //聚合的名称
//定义avg聚合,指定字段为price
SumAggregationBuilder aggregationBuilder = AggregationBuilders.sum(aggName).field("price");
aggregationBuilder.missing("100");
searchSourceBuilder.aggregation(aggregationBuilder); //添加聚合
searchRequest.source(searchSourceBuilder); //设置查询请求
//执行查询
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//获取聚合结果
Aggregations aggregations = searchResponse.getAggregations();
//获取value_count聚合返回的对象
Sum sum = aggregations.get(aggName);
String key=sum.getName();
double value = sum.getValue();
log.info("key={},value={}",key,value);
}

- 0
- 0
-
分享