
SpringBoot整合多数据源
SpringBoot整合多数据源
方案一 自定义多数据源实现类
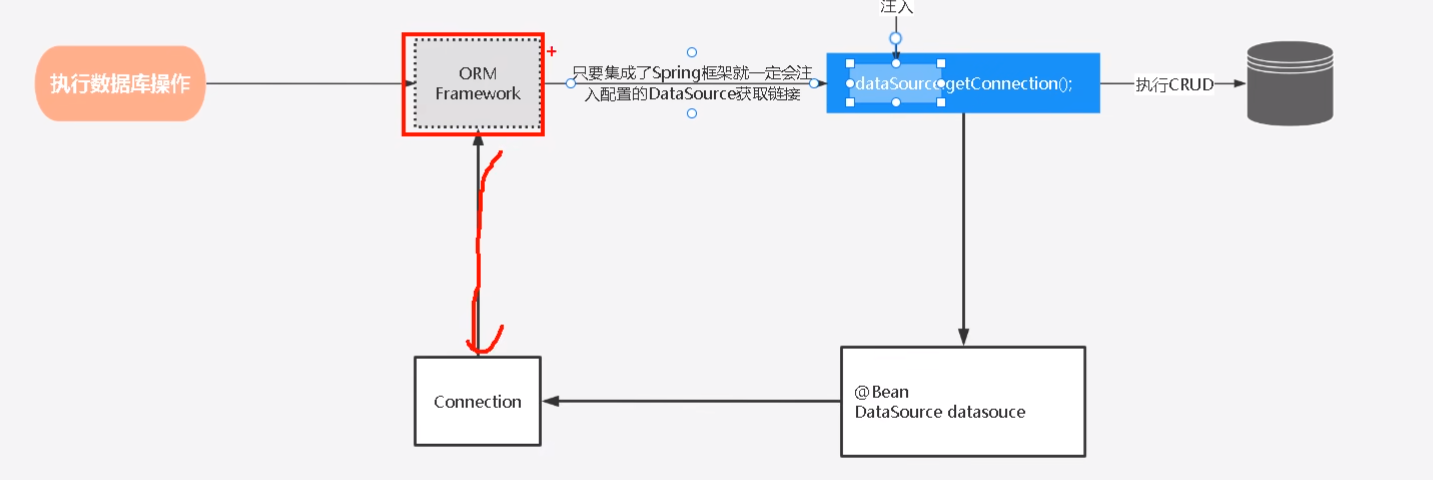
我们在调用任何持久层的框架,都是基于JDBC进行操作的,只要集成了Spring框架就一定会注入配置的DataSource获取连接dataSource.getConnection()。既然是我们配置的,我们可以实现一个自定义的DataSource,然后动态提供数据源。说干就干
那我们实现DataSource这个接口,实现getConnection方法即可,会返回一个Connection对象。我们在这个方法中根据业务需求动态提供不同数据源的Connection对象即可。实现逻辑如下:
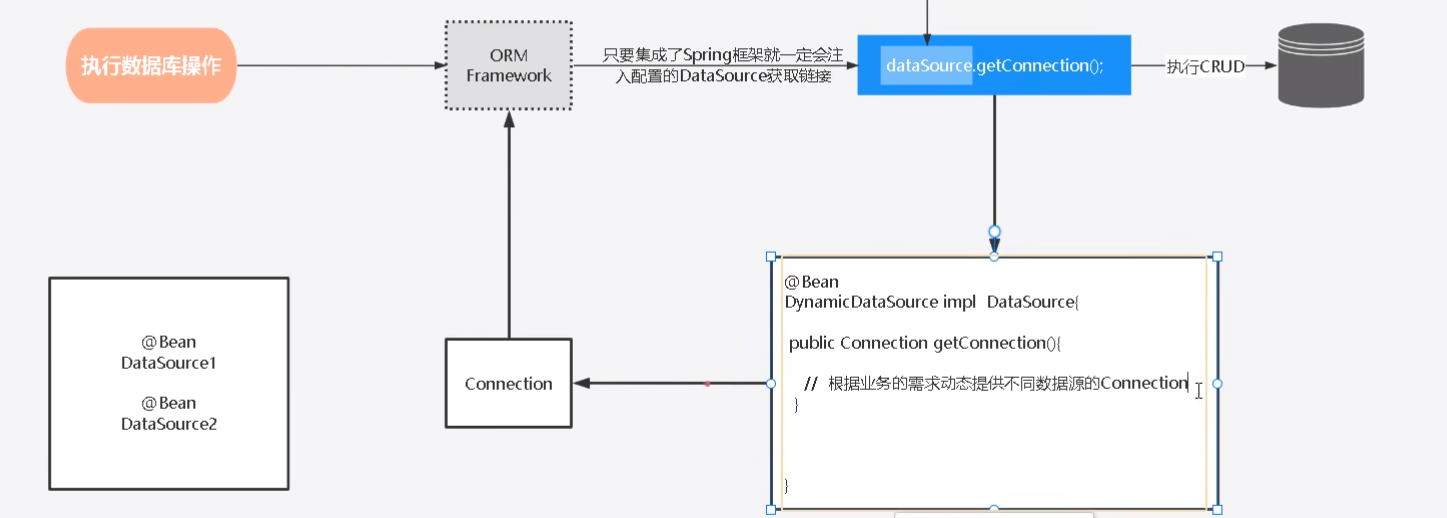
我们可以通过一个静态的标识去判断,比如如果是Write,那就返回datasource1,如果是Read,就返回datasource2。为了保证线程安全,可以使用ThreadLocal包裹一下。
配置文件(模拟两个数据源)
server:
port: 8899
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
datasource1:
url: jdbc:mysql://localhost:3306/datasource1?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
druid:
min-idle: 1
initial-size: 1
max-active: 20
test-on-borrow: true
driver-class-name: com.mysql.cj.jdbc.Driver
datasource2:
url: jdbc:mysql://localhost:3306/datasource2?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
druid:
min-idle: 1
initial-size: 1
max-active: 20
test-on-borrow: true
driver-class-name: com.mysql.cj.jdbc.Driver
mybatis:
mapper-locations: classpath:mapper/*.xml
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
数据源配置
@Configuration
public class DataSourceConfig {
@Bean
@ConfigurationProperties(prefix = "spring.datasource.datasource1")
public DataSource dataSource1(){
//底层会自动拿到spring.datasource中的配置,创建一个DruidDataSource
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.datasource2")
public DataSource dataSource2(){
return DruidDataSourceBuilder.create().build();
}
}
数据源切换的配置类(实现DataSource接口)
@Component
@Primary //将该Bean设置为主要注入Bean
public class DynamicDataSource implements DataSource, InitializingBean {
//当前使用的数据源标识,用ThreadLocal保持线程安全
public static ThreadLocal<Operation> name=new ThreadLocal<>();
//写
@Autowired
DataSource dataSource1;
//读
@Autowired
DataSource dataSource2;
@Override
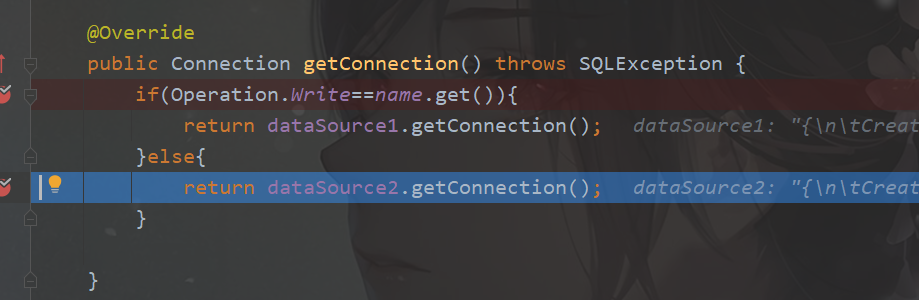
public Connection getConnection() throws SQLException {
if(Operation.Write==name.get()){
return dataSource1.getConnection();
}else{
return dataSource2.getConnection();
}
}
//...省略非关键的代码
@Override
public void afterPropertiesSet() throws Exception {
//初始化
//默认数据源标识是写
name.set(Operation.Write);
}
}
我们这样子配置相当于有三个DataSource了,所以这里使用@Primary注解将我们自定义的DynamicDataSource作为主要的Bean进行注入,即出现了相同类型的dataSource,就会使用DynamicDataSource。
这里的数据源标识通过ThreadLocal保证线程安全。
实现InitializingBean接口,是Bean初始化回调的一个方法,可以做一些初始化,我们这里设置默认表示是Write,也就是写的那个数据源datasource1。
Operation是我自定义的枚举类:
public enum Operation {
READ,
Write
}
getConnection()方法中我们通过判断标识来动态切换数据源,如果是读操作,使用dataSource2,如果是写操作,使用dataSource1。
测试的Controller
@RestController
@RequestMapping("/friend")
public class FriendController {
@Autowired
private FriendService friendService;
@GetMapping("select")
public List<Friend> select(){
DynamicDataSource.name.set(Operation.READ);
return friendService.list();
}
@GetMapping("insert")
public void insert(){
DynamicDataSource.name.set(Operation.Write);
Friend friend = new Friend();
friend.setName("张三");
friendService.save(friend);
}
}
我们在方法总动态设置数据源标识,然后开始测试:
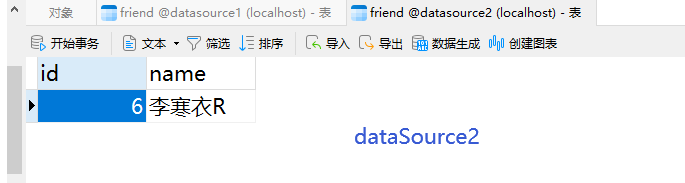
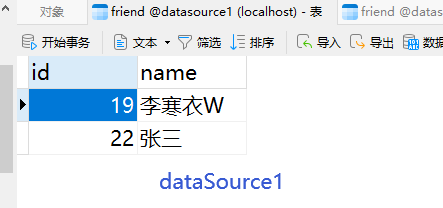
读请求:
http://localhost:8899/friend/select
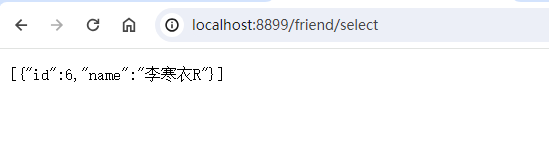
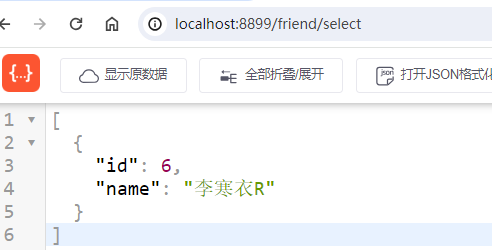
可以看到,返回的是从库(dataSource2)的信息,通过下图的断点也可以很清楚的看到结果。
总结
- 实现DataSource接口比较粗糙,稳定性不高。
- 这种硬编码的方法耦合度也太高了,对后期的维护造成很大的麻烦生产中肯定不是这种写法。
方案二 AbstractRoutingDataSource(*)
流程分析
通过AbstractRoutingDataSource抽象类实现多数据源的切换,我们继承这个抽象类写实现即可。
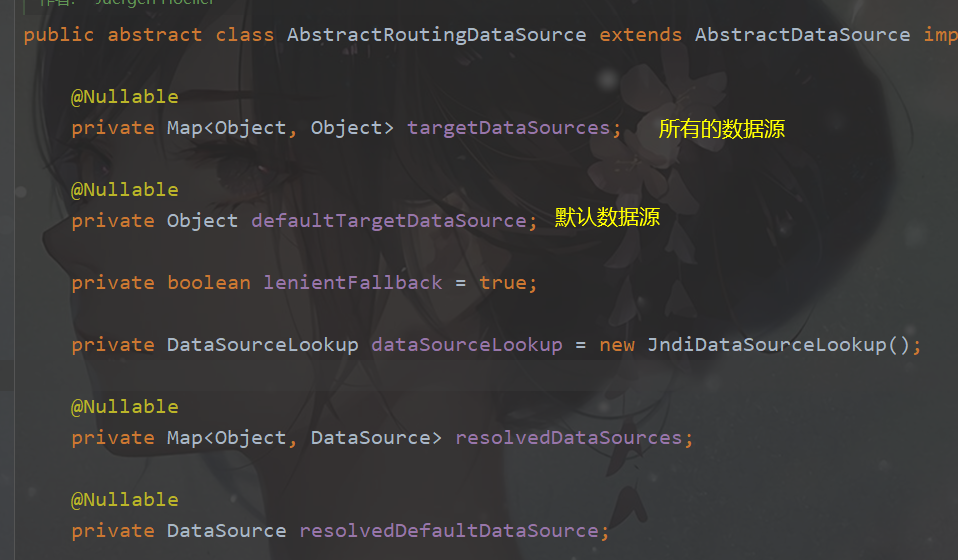
通过源码我们可以看到,自己需要做的是初始化这个targetDataSources和defaultTargetDataSource。
查看下流程:
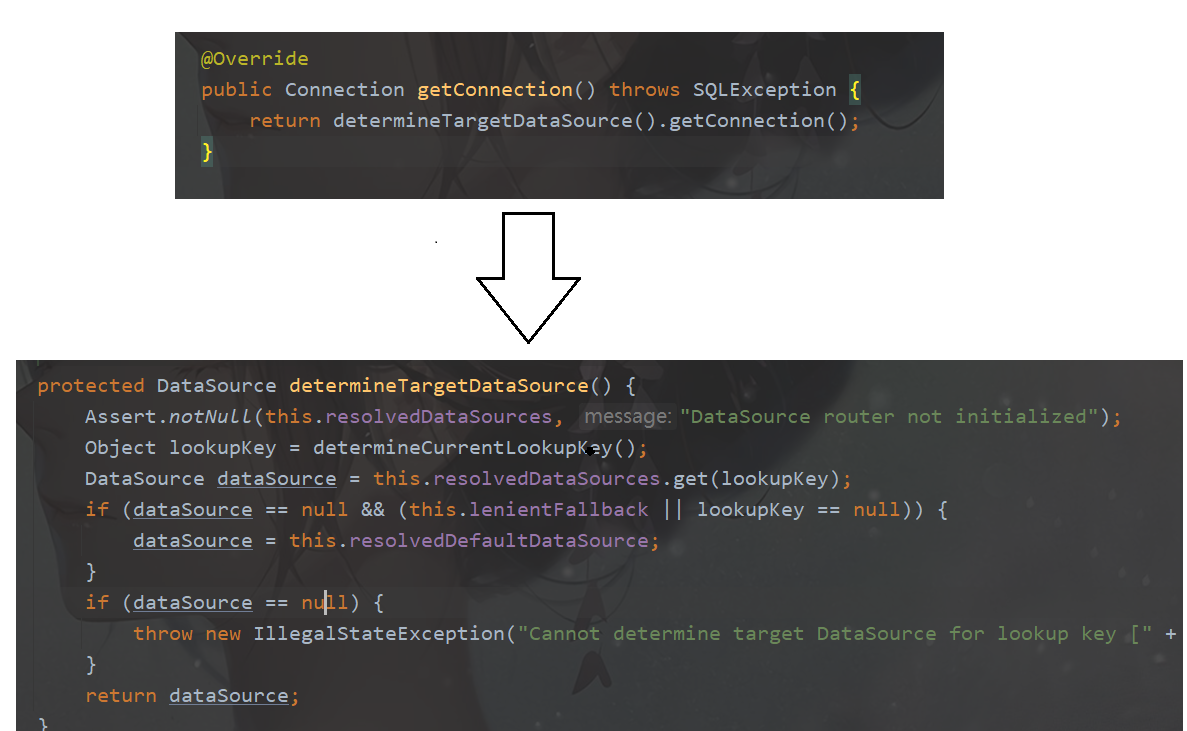
通过源码可以发现,getConnection()方法通过调用determineTargetDataSource()确定最终的具体的数据源,这个方法就需要我们自己去是西安了,然后通过模板方法determineCurrentLookupKey返回数据源标识。

继承AbstractRoutingDataSource抽象类
@Component
@Primary //将该Bean设置为主要注入Bean
public class DynamicDataSource extends AbstractRoutingDataSource {
//当前使用的数据源标识,用ThreadLocal保持线程安全
public static ThreadLocal<Operation> name=new ThreadLocal<>();
//写
@Autowired
DataSource dataSource1;
//读
@Autowired
DataSource dataSource2;
@Override
protected Object determineCurrentLookupKey() {
return name.get();
}
@Override
public void afterPropertiesSet() {
//为targetDataSources初始化所有数据源
Map<Object,Object> targetDataSources=new HashMap<>();
targetDataSources.put(Operation.Write,dataSource1);
targetDataSources.put(Operation.READ,dataSource2);
super.setTargetDataSources(targetDataSources);
//为defaultTargetDataSource设置默认数据源
super.setDefaultTargetDataSource(dataSource1);
super.afterPropertiesSet();
}
}
只需要实现determineCurrentLookupKey方法,并在方法中返回数据源标识即可。
还需要初始化所有的数据源targetDataSources和默认数据源defaultTargetDataSource,我们在afterPropertiesSet方法中初始化即可。父类已经实现这个方法了,我们就直接重写即可。
通过下面这两行代码设置不同标识对应的数据源。
targetDataSources.put(Operation.Write,dataSource1);
targetDataSources.put(Operation.READ,dataSource2);
测试
读请求:http://localhost:8899/friend/select

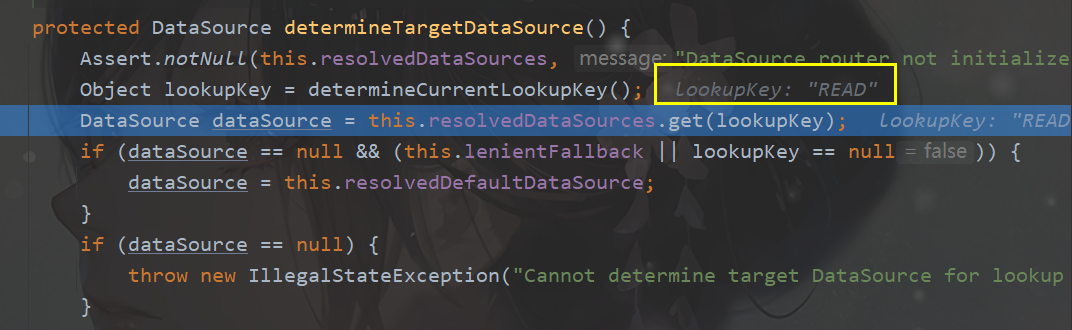
其中resolvedDataSources已经在初始化的时候赋值过了:

这个时候已经拿到了Connection,可以执行CRUD了。
总结
通过继承AbstractRoutingDataSource,设置初始化所有数据源,通过模板方法determineCurrentLookupKey返回当前数据源标识即可。
但是设置数据源标识的代码还是耦合在代码当中,需要优化。
方案三 通过mybatis插件实现
@Signature表示要为底层的那个对象进行代理。mybatis是通过Executor执行器实现数据库操作。
具体请看mybatis拦截器相关知识。
@Component
@Intercepts({
@Signature(type = Executor.class, method = "update", args = {MappedStatement.class,Object.class}),
@Signature(type = Executor.class, method = "query", args = {MappedStatement.class, Object.class,RowBounds.class,ResultHandler.class})
})
public class DynamicDataSourcePlugin implements Interceptor {
@Override
public Object intercept(Invocation invocation) throws Throwable {
//拿到当前方法(update、query)所有参数
Object[] objects = invocation.getArgs();
//MappedStatement 封装CRUD所有的元素和SQL
MappedStatement ms = (MappedStatement) objects[0];
//读方法
if (ms.getSqlCommandType().equals(SqlCommandType.SELECT)) {
DynamicDataSource.name.set(Operation.READ);
} else {
//写方法
DynamicDataSource.name.set(Operation.Write);
}
//修改当前线程要选择数据源的key
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
//判断是否拦截这个类对象(根据@intercepts注解决定),然后决定是否返回一个代理对象还是返回原对象
if (target instanceof Executor) {
return Plugin.wrap(target, this);
} else {
return target;
}
}
}
通过MappedStatement可以判断执行的是查询还是写操作,然后我们就可以动态的设置数据源标识了。
这个时候就可以将编程式设置数据源标识的代码注释掉了
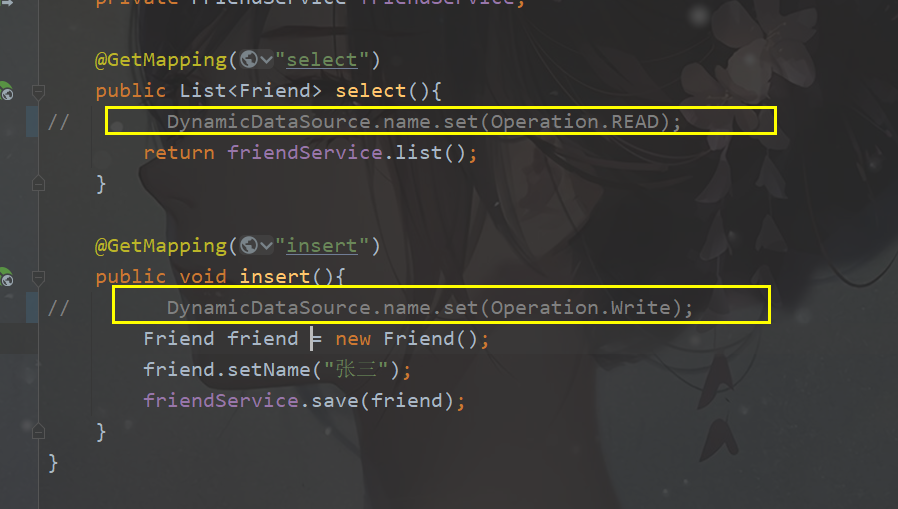
查询操作:
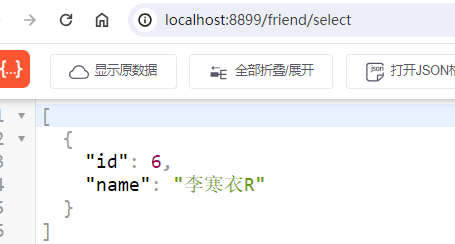
新增操作:http://localhost:8899/friend/insert
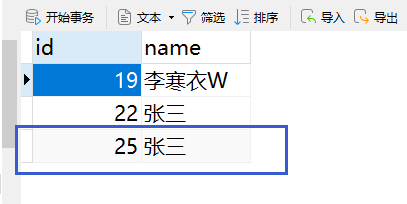
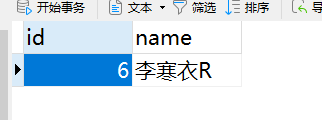
可以看到,主库新增了一条数据,从库的数据没变。
我这里还想看下interceptors的自动注入是不是我们配置的这个DynamicDataSourcePlugin,打断点启动:
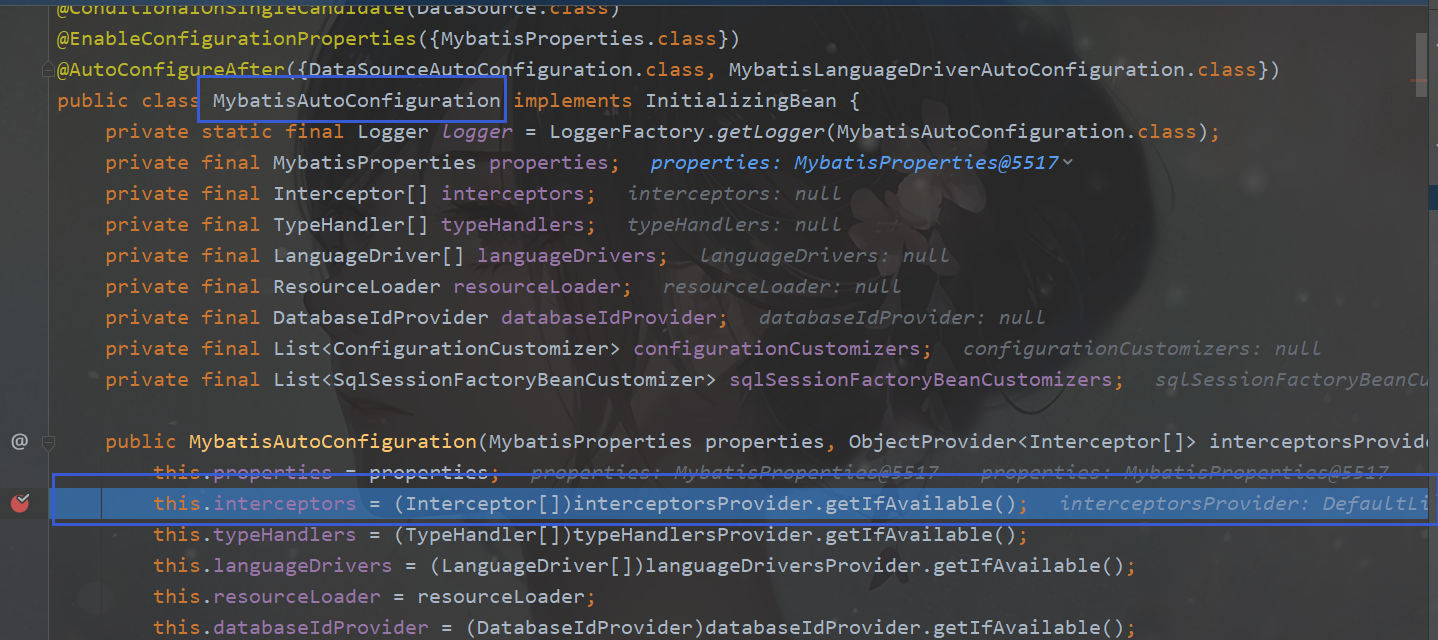
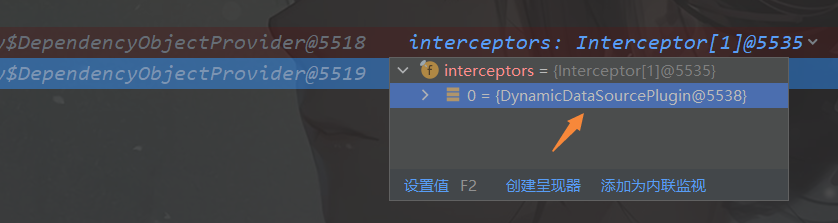
MybatisAutoConfiguration这个自动配置类中使用的就是我们自定义的,没问题。
方案四 AOP+自定义注解切换数据源(*)
mybatis插件适用于读写分离的场景,如果是不同业务的数据源,还要根据数据库表名判断是哪个数据库,可以实现但是比较麻烦,sql如果是多表查询,就比较麻烦了,所以这里使用AOP+自定义注解。
启动AOP
添加依赖
<!--AOP-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
</dependency>
要使用AOP,启动类先加个注解EnableAspectJAutoProxy。
自定义注解
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME) //保留方式
public @interface WR {
Operation value() default Operation.Write;
}
我们可以通过反射的去获取类上边是否加了这个注解。我们在这里设置value的默认值为Write。
方法上边添加该注解(实际使用中可能放在类上边更合适),value设置数据源标识即可。
@Service
public class FriendServiceImpl implements FriendService {
@Autowired
private FriendMapper friendMapper;
@Override
@WR(Operation.READ)
public List<Friend> list() {
return friendMapper.list();
}
@Override
@WR(Operation.Write)
public void save(Friend friend) {
friendMapper.save(friend);
}
}
声明一个切面
@Component
@Aspect
public class DynamicDataSourceAspect {
//前置通知
@Before("within(com.xtt.dynamic.datasource.service.impl.*) && @annotation(wr)")
public void before(JoinPoint joinPoint, WR wr){
Operation name = wr.value();
DynamicDataSource.name.set(name);
System.out.println(name);
}
//环绕通知
}
这里使用前置通知和环绕通知均可。根据注解中的元数据动态设置数据源的标识即可。
切点表达式:within(com.xtt.dynamic.service.impl.*) && @annotation(wr),注解肯定是要匹配的,使用 @annotation(wr),我们只希望匹配service包下加了这个注解的类,所以加上within(com.xtt.dynamic.datasource.service.impl.*)。
测试
http://localhost:8899/friend/select


可以看到,查询操作确实是将数据源标识设置为了Read(我们自定义的枚举值)
放行断点之后也返回了正确的信息。

这种方式适用于不同业务的多数据库场景
方案五 dynamic-datasource插件(*)
文档地址:https://www.kancloud.cn/tracy5546/dynamic-datasource
dynamic-datasource-spring-boot-starter 是一个基于springboot的快速集成多数据源的启动器
特性:
- 支持 数据源分组 ,适用于多种场景 纯粹多库 读写分离 一主多从 混合模式。
- 支持数据库敏感配置信息 加密(可自定义) ENC()。
- 支持每个数据库独立初始化表结构schema和数据库database。
- 支持无数据源启动,支持懒加载数据源(需要的时候再创建连接)。
- 支持 自定义注解 ,需继承DS(3.2.0+)。
- 提供并简化对Druid,HikariCp,BeeCp,Dbcp2的快速集成。
- 提供对Mybatis-Plus,Quartz,ShardingJdbc,P6sy,Jndi等组件的集成方案。
- 提供 自定义数据源来源 方案(如全从数据库加载)。
- 提供项目启动后 动态增加移除数据源 方案。
- 提供Mybatis环境下的 纯读写分离 方案。
- 提供使用 spel动态参数 解析数据源方案。内置spel,session,header,支持自定义。
- 支持 多层数据源嵌套切换 。(ServiceA >>> ServiceB >>> ServiceC)。
- 提供 基于seata的分布式事务方案 。
- 提供 本地多数据源事务方案。
约定:
- 本框架只做 切换数据源 这件核心的事情,并不限制你的具体操作,切换了数据源可以做任何CRUD。
- 配置文件所有以下划线
_分割的数据源 首部 即为组的名称,相同组名称的数据源会放在一个组下。- 切换数据源可以是组名,也可以是具体数据源名称。组名则切换时采用负载均衡算法切换。
- 默认的数据源名称为 master ,你可以通过
spring.datasource.dynamic.primary修改。- 方法上的注解优先于类上注解。
- DS支持继承抽象类上的DS,暂不支持继承接口上的DS。
添加依赖
这里只给出关键依赖,其他的就先不放出了,都是基础依赖。
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>dynamic-datasource-spring-boot-starter</artifactId>
<version>3.5.0</version>
</dependency>
添加配置
这里我就用一个主库,一个从库来测试下,当然也可以配置一主多从的方式
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://localhost:3306/datasource1?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver # 3.2.0开始支持SPI可省略此配置
slave_1:
url: jdbc:mysql://localhost:3306/datasource2?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# slave_2:
# url: ENC(xxxxx) # 内置加密,使用请查看详细文档
# username: ENC(xxxxx)
# password: ENC(xxxxx)
# driver-class-name: com.mysql.jdbc.Driver
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2
官方给的示例配置如下:
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master
strict: false #严格匹配数据源,默认false. true未匹配到指定数据源时抛异常,false使用默认数据源
datasource:
master:
url: jdbc:mysql://xx.xx.xx.xx:3306/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver # 3.2.0开始支持SPI可省略此配置
slave_1:
url: jdbc:mysql://xx.xx.xx.xx:3307/dynamic
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
slave_2:
url: ENC(xxxxx) # 内置加密,使用请查看详细文档
username: ENC(xxxxx)
password: ENC(xxxxx)
driver-class-name: com.mysql.jdbc.Driver
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2
多数据源使用测试
这里的主库和从库并不是搭建的主从复制集群,只是为了方便看到结果用了两个数据库而已。
实体类
@Data
@AllArgsConstructor
@NoArgsConstructor
@EqualsAndHashCode(callSuper = false)
public class Friend {
private Long id;
private String name;
}
随便写几个测试的controller
@RestController
@RequestMapping("/friend")
public class FriendController {
@Autowired
private FriendService friendService;
@GetMapping("select")
public List<Friend> select(){
// DynamicDataSource.name.set(Operation.READ);
return friendService.list();
}
@GetMapping("insert")
public void insert(){
// DynamicDataSource.name.set(Operation.Write);
Friend friend = new Friend();
friend.setName("张三");
friendService.save(friend);
}
@GetMapping("save")
public void save(){
Friend friend = new Friend();
friend.setName("赵玉真");
friendService.saveAll(friend);
}
}
实现类中加上@DS注解
这个注解可以加在类上边,也可以加在方法上边。这里配置的意思是,list方法操作从库,save方法操作主库。
//读--读库
@Override
@DS("slave_1") //从库,如果按照下划线方式配置了多个,可以指定前缀即可(组名)
public List<Friend> list() {
return friendMapper.list();
}
//写-写库
@Override
@DS("master")
public void save(Friend friend) {
friendMapper.save(friend);
}
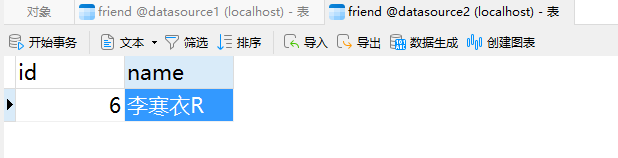
主库(datasource1)和从库(datasource2)中分别有一条数据:

查询请求:
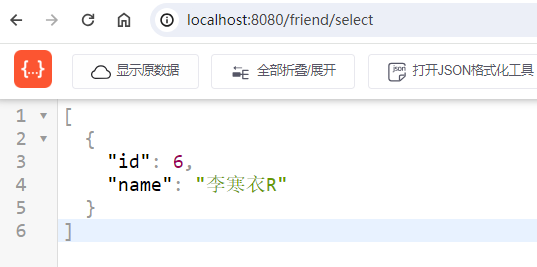
可以看到,结果是从库中的数据
新增数据的请求:`http://localhost:8080/friend/insert
从库的数据没变
主库新增了一条数据。

本地事务测试
我现在要给主库和从库都添加数据,且任意一个失败都要出发事务回滚,这在平时的SpringBoot注解是做不到的,除非通过编程式事务或者AOP解决,但是dynamic-datasource已经封装好了这些逻辑。

我现在saveW操作主库,saveR操作从库,我通过@DSTransactional注解实现事务控制,只要saveW和saveR有任何一个发生了异常,这两个数据库事务都会回滚。
我在saveR中模拟一个运行时异常,开始测试:
然后看数据库有没有新增:
主库:
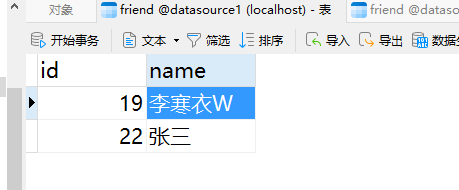
从库:

都没有新增数据,说明事务回滚成功了。
注意事项:
本地事务实现很简单,就是循环提交,发生错误,循环回滚。 我们默认的前提是数据库本身不会异常,比如宕机。
如数据在回滚的过程突然宕机,本地事务就会有问题。如果你需要完整分布式方案请使用seata方案。
- 不支持spring原生事务,不支持spring事务,不支持spring事务,可分别使用,千万不能混用。
- 再次强调不支持spring事务注解,可理解成独立写了一套事务方案。
- 只适合简单本地多数据源场景, 如果涉及异步和微服务等完整事务场景,请使用seata方案。
- 暂时不支持更多配置,如只读,如spring的传播特性。 后续会根据反馈考虑支持。4.1.4会开始支持在类上使用.
如果是分布式事务,需要使用seta,以前写过这种文章,后面再复习。
- 0
- 0
-
分享